
Character Encoding
by Bob Weiss
Happy Pi Day. It is also Albert Einstein’s birthday.
As we discussed in our first article, many of the cybersecurity certifications that I teach have content that involves the uses of encoding, code injection, directory transversal, and scripting. These concepts can be difficult to grasp, and the exam questions can be challenging to answer correctly. This series of articles is designed to help you understand the basic concepts, and how these get used both securely and maliciously. I am planning to show examples to help you identify these types of use cases or exploits when they show up in an exam question.
This is the second multi-part series of articles. In the first article we started with the uses of binary and other numbering systems. In this article we will learn how these are used to create character sets of upper-case and lower-case letters, numbers, and symbols. In the following articles, we will look at ways that encoding is used to modify or obfuscate web addresses and hyperlinks. We will look at encoding as it is used in different command injection attacks, and directory traversal exploits.
One housekeeping tip: If you click on the images, they will expand to full size on a separate page. You may then right click on the image and save it as a study aid.
ASCII Encoding
Let’s move on to ASCII encoding for letters, numbers, and symbols. ASCII is an acronym for the American Standard Code for Information Interchange. ASCII was descended from telegraph code, and was first used as a 7 bit used in teleprinter systems like the Telex. The development of ASCII began in 1961. ASCII encodes 128 specified characters as 7 bit binary numbers. This includes digits 0-9, upper and lower case letters from A to Z and a to z, and punctuation marks. It also includes 33 non-printing Control Codes, hold overs from the teletype, such as CR carriage return, LF line feed and tabs
For example, lowercase i would be represented in the ASCII encoding by binary 1101001 = hexadecimal 69 (i is the ninth letter) = decimal 105. This resource from Rapid Tables can convert binary, octal, decimal, and hexadecimal plus a number of character sets to and from each other.
The ASCII Table of characters follows.
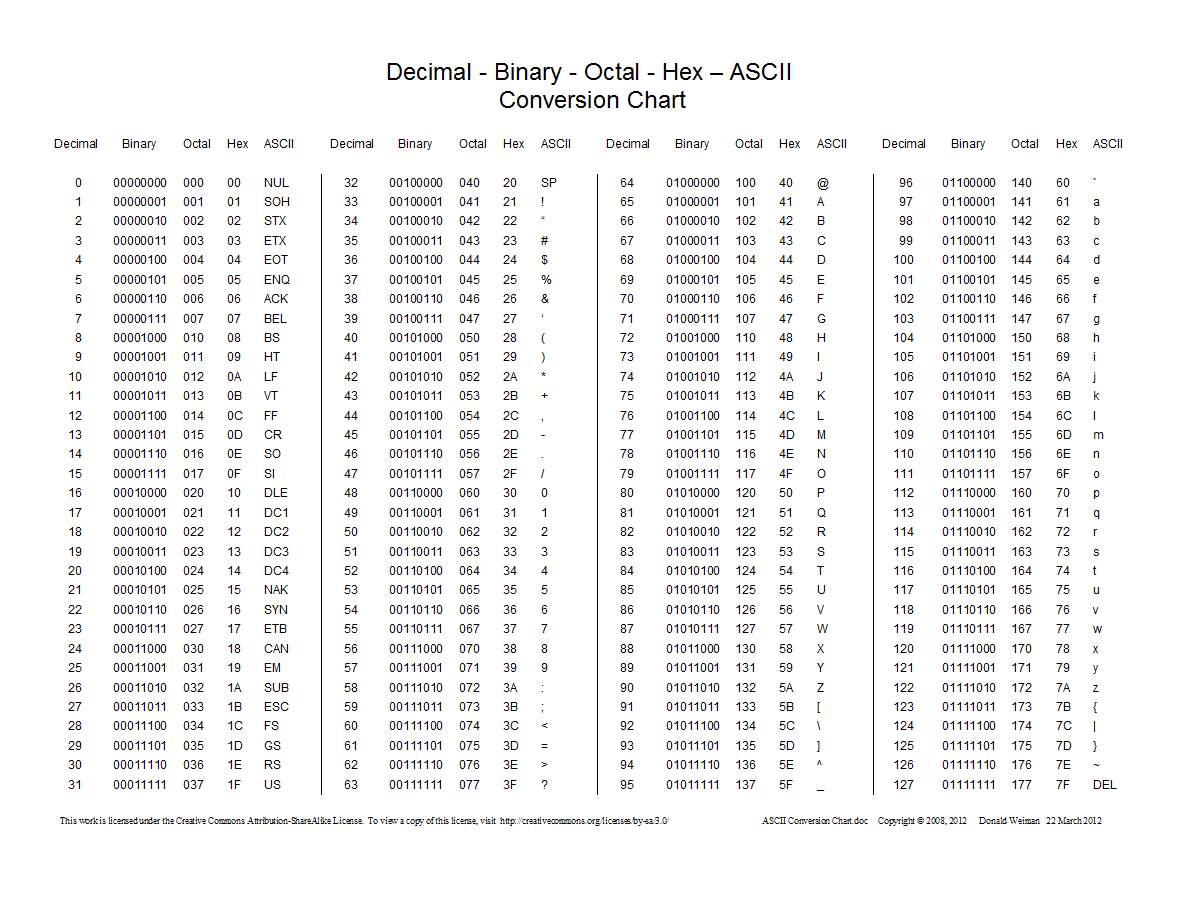
The first column of 32 characters, and the first character in column two, are control characters. These are not used as printable characters, but as control codes and commands for devices. These were created for teleprinters, and many of these codes are obsolete but some of these commands are still in use. Characters 34 through 47 are punctuation. Characters 48 to 57 are numbers. 58 to 64 are mathematical symbols. 65 through 90 are capital letters. 91 to 96 are braces and other diacritical marks. 97 through 122 are lower case letters. 123 to 127 are additional braces and the DEL symbol.
Unicode Encoding
As computers developed 8, 16, 32 and 64 bit processing, ASCII began to use 8 bits per character vs. 7 bits. This became known as extended ASCII. Eventually, ASCII was replaced with Unicode (UTF-8, UTF-16, UTF-32), which is the current standard for text and character display. The additional capacity allows for encoding all 1,112,064 valid characters, including non English letters and symbols common in European languages, as well as Cyrillic, Chinese, Japanese, Korean and other character sets. The first 128 characters are the same in ASCII and was done to provide backward compatibility. This excerpt from Wikipedia explains how Unicode works:
“The first 128 code points (ASCII) need one byte. The next 1,920 code points need two bytes to encode, which covers the remainder of almost all Latin-script alphabets, and also IPA extensions, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N’Ko alphabets, as well as Combining Diacritical Marks. Three bytes are needed for the rest of the Basic Multilingual Plane (BMP), which contains virtually all code points in common use, including most Chinese, Japanese and Korean characters. Four bytes are needed for code points in the other planes of Unicode, which include less common CJK characters, various historic scripts, mathematical symbols, and emoji (pictographic symbols).
A “character” can take more than 4 bytes because it is made of more than one code point. For instance a national flag character takes 8 bytes since it’s “constructed from a pair of Unicode scalar values” both from outside the BMP.
Examples
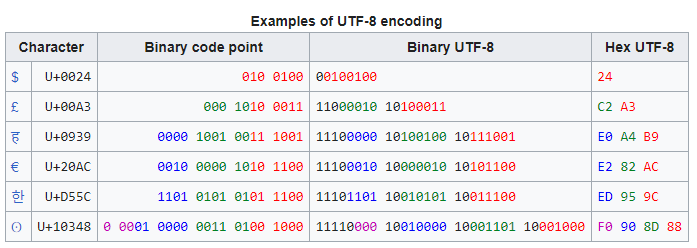
Consider the encoding of the euro sign, €:
- The Unicode code point for € is U+20AC.
- As this code point lies between U+0800 and U+FFFF, this will take three bytes to encode.
- Hexadecimal 20AC is binary 0010 0000 1010 1100. The two leading zeros are added because a three-byte encoding needs exactly sixteen bits from the code point.
- Because the encoding will be three bytes long, its leading byte starts with three 1s, then a 0 (1110…)
- The four most significant bits of the code point are stored in the remaining low order four bits of this byte (11100010), leaving 12 bits of the code point yet to be encoded (…0000 1010 1100).
- All continuation bytes contain exactly six bits from the code point. So the next six bits of the code point are stored in the low order six bits of the next byte, and 10 is stored in the high order two bits to mark it as a continuation byte (so 10000010).
- Finally the last six bits of the code point are stored in the low order six bits of the final byte, and again 10 is stored in the high order two bits (10101100).
The three bytes 11100010 10000010 10101100 can be more concisely written in hexadecimal, as E2 82 AC.
The following table summarizes this conversion, as well as others with different lengths in UTF-8. The colors indicate how bits from the code point are distributed among the UTF-8 bytes. Additional bits added by the UTF-8 encoding process are shown in black.”
Now you know how numbers and letters are represented in a computer system. Hopefully this article has been helpful in understanding the uses of binary, octal, and hexadecimals numbering system, and how they are used to create character sets of alphabetical letters, numbers, and symbols. In the next article we will see how encoding works when used in a URL (Uniform Resource Locator), more commonly know as a web address or hyperlink.
Share



MAR
About the Author:
I am a cybersecurity and IT instructor, cybersecurity analyst, pen-tester, trainer, and speaker. I am an owner of the WyzCo Group Inc. In addition to consulting on security products and services, I also conduct security audits, compliance audits, vulnerability assessments and penetration tests. I also teach Cybersecurity Awareness Training classes. I work as an information technology and cybersecurity instructor for several training and certification organizations. I have worked in corporate, military, government, and workforce development training environments I am a frequent speaker at professional conferences such as the Minnesota Bloggers Conference, Secure360 Security Conference in 2016, 2017, 2018, 2019, the (ISC)2 World Congress 2016, and the ISSA International Conference 2017, and many local community organizations, including Chambers of Commerce, SCORE, and several school districts. I have been blogging on cybersecurity since 2006 at http://wyzguyscybersecurity.com